本文为节选内容
如需更多报告,联系客服
或扫码获取报告

1.GPT与o1验证了训练侧和推理侧算力投入的重要性
(1)OpenAI是一家致力于推动通用人工智能惠及人类的企业。OpenAI创立于2015年,最早为非营利组织,创始人包括萨姆·奥尔特曼(Sam Altman)、彼得·蒂尔(Peter Thiel)、里德·霍夫曼(Reid Hoffman)和埃隆·马斯克(Elon Musk)等,其中大多都有丰富的技术和商业背景,2016年,OpenAI发布首个产品OpenAI Gym和Universe,2018年,GPT系列模型首次亮相,采用Transformer架构,参数规模达到1.17亿,后续该系列模型不断迭代,参数规模、训练数据、上下文窗口大小呈指数级增长,模型性能相应也有显著提升,此外,GPT系列模型也从最初单一的文本模态迭代成为GPT-4系列的多模态大模型,2025年,OpenAI将推出GPT-4.5大模型。除GPT系列外,OpenAI还推出了深度推理模型OpenAI o1、o3模型,以及文生视频模型Sora等。
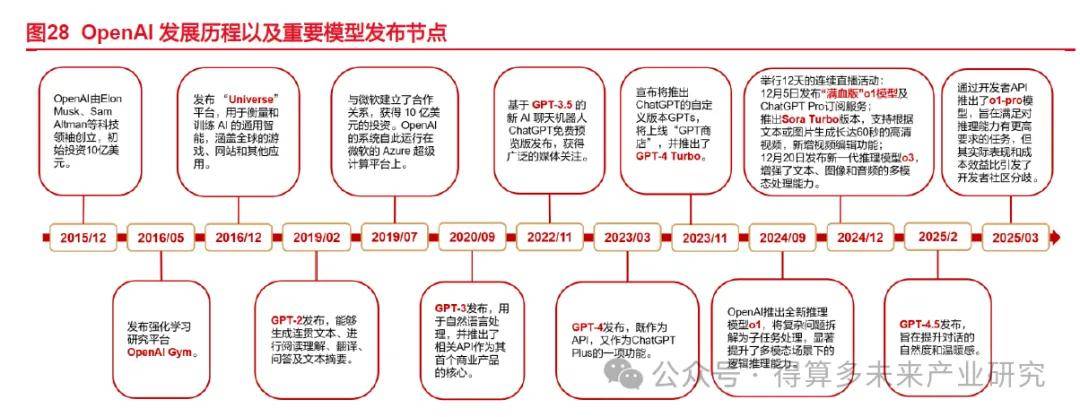
(2)基于GPT-3.5的ChatGPT的发布推动了AI技术的普及和AI产业的变革,是人工智能的重要里程碑之一。2022年11月30日,OpenAI正式发布聊天机器人ChatGPT,基于GPT-3.5架构,能够回答问题、创作文章、编程,甚至可以模仿人类的对话风格,颠覆了人们对于通用大语言模型的认知。ChatGPT发布后,仅仅用了2个月用户数量便达到亿级,增速超越了TikTok、Instagram等全球头部消费级应用。ChatGPT的发布标志着自然语言处理(NLP)技术的重大进步,改善了人机交互体验,显著提高了生产力,推动了AI行业变革。
(3)GPT系列模型着重于预训练阶段的Scaling law,在预训练阶段投入了大部分算力资源,在后训练阶段采用SFT、RFHL等形式,整体来说更适合解决通识类知识。以GPT-4为例,其整体参数规模约为GPT-3的10倍,根据Semianalyst的《GPT-4 Architecture, Infrastructure, Training Dataset, Costs, Vision, MoE》文章中透露,GPT4在预训练阶段使用了25000张40G的英伟达A100训练了90天以上,总耗费约6300万美元,而模型能力也因此基本来自预训练阶段学习理解的大量多模态信息和知识,所以GPT系列模型针对问题能够迅速反应并给出答案,擅长处理的也基本是通识类的知识。在后训练阶段,GPT采用SFT、RFHL(人类提供偏好反馈数据从而训练强化学习的奖励模型)方式,提升模型的实际应用效果。
(4)Open AI于2024年9月发布OpenAI o1模型,可以执行复杂的推理任务,MMLU评分超越一众大模型。o1模型在回答问题之前会形成一条内部思维链(Chain of Thought),模拟人类的思考过程,其在物理、化学和生物学这些具有挑战性的基准任务上的表现与博士生相似,在数学和编码方面表现同样出色。他的MMLU(知识问答,评估LLM的知识和推理能力)评分、Math(含代数、微积分、几何、概率等多个领域)评分、GPQA Diamond(全面的框架,测试模型在多种推理场景下的能力)评分均超过了当时的主流大模型,如Gemini 2.0 Pro Experimental、Hunyuan-TurboS、Claude 3.5 Sonnet等,对比GPT-4o也有显著提升。
(5)o1模型的发布证明了推理侧的算力资源投入同样重要,“Scaling Law”在推理阶段或同样适用。o1模型引入的思维链类似人类在回答困难问题之前的长时间思考,通过训练时的强化学习,o1能够锻炼其思维链并改进其使用的策略,它还能够识别并改正错误,将棘手的问题拆分成更简单的步骤,如果目前的方式不奏效,o1还会尝试不同的解决方式。上述思维链让o1的推理能力大幅增强。从下图可知,当推理侧的算力资源增加时,模型处理问题的准确度显著提升,代表着类似于预训练阶段的“Scaling Law”在推理阶段也同样兑现了。
(6)未来,GPT系列与o1为代表的深度推理系列模型或将互相补充。相比GPT-4o,o1在具有挑战性的推理密集型任务中都有更为出色的表现,GPT系列类似于思维中的浅层、快速反应系统,能迅速处理日常生活中的直觉性反应和基础认知任务,有更好的多模态交互能力,更大的参数规模、更优质的训练数据、优化后的模型架构是GPT系列模型的发展方向。而对于以o1为代表的深度推理系列模型来说,类似于思维中的逻辑性系统,更擅长复杂的分析和经过深思熟虑后的决策提供,需要更多的推理时间和大量的思维链分析过程,后续发展更注重后训练阶段的“思考模式”优化,以及推理阶段更多的算力资源投入。这两类模型相互补充,GPT类模型可以作为o1类模型的基础模型增强通识,o1类模型可以为GPT类模型生成高质量的推理数据,未来两类模型或共同发展,相互促进。
2.DeepSeek创新性地实现了成本更低的训练
(1)DeepSeek大模型的发布进一步带动AI大模型热潮。DeepSeek,全称杭州深度求索人工智能基础技术研究有限公司,由量化私募管理机构幻方量化成立,专注于开发先进的大语言模型和相关技术。DeepSeek创始人为梁文峰,有丰富的电子信息和人工智能相关背景。2024年12月26日,DeepSeek-V3发布,训练成本约为GPT-4o的1/10,同时性能比肩顶尖闭源模型,DeepSeek-R1于2024年1月发布,性能对标OpenAI-o1正式版。DeepSeek的发布挑战了纯算力路径,发布后海内外各大厂商争相本地部署DeepSeek,云服务商也相继入局,掀起AI云与端热潮,算力芯片、服务器、算力云等产业链有望长期收益。

(2)DeepSeek大模型发布后仅用七天用户增长一亿,海内外头部厂商纷纷入场布局。相比ChatGPT先前两个月的记录,DeepSeek在DeepSeek-R1发布后,仅用七天就实现了用户增长一亿的成绩,远超各大头部APP。其卓越的性能表现和开源特性,吸引了全球AI开发者和海内外头部厂商布局,华为云与硅基流动联合首发并上线基于华为云昇腾云服务的DeepSeek R1/V3推理服务,腾讯云则将R1大模型一键部署至高性能应用服务HAI上,开发者仅需3分钟就能接入调用;海外AI芯片头部厂商英伟达宣布DeepSeek-R1模型登陆NVIDIA NIM,AMD宣布已将新的DeepSeek-V3模型集成到Instinct MI300X GPU上,针对AI推理进行了优化,云服务龙头亚马逊和微软也纷纷接入DeepSeek-R1,共同推动AI技术的迅速发展和应用普及。
(3)DeepSeek-V3性能对齐海外领军闭源模型,训练成本和定价却远低于后者。DeepSeek-V3于2024年12月底发布,为开源自研MoE模型,共671B参数,激活37B,在14.8T token上进行了预训练。根据测试,DeepSeek-V3的多项评测成绩超越了Qwen2.5-72B和Llama-3.1-405B等其他开源模型,并在性能上和世界顶尖的闭源模型GPT-4o以及Claude-3.5-Sonnet不分伯仲。从API定价看,DeepSeek-V3每百万输入tokens 0.5元(缓存命中)/ 2元(缓存未命中),每百万输出tokens 8元,远低于其他厂商的头部大模型。从训练成本看,根据官方的《DeepSeek-V3 Technical Report》,在预训练阶段,在每万亿个 token上训练DeepSeek-V3只需要18万个H800 GPU小时,即在拥有2048个H800 GPU的集群上需要3.7天。因此,预训练阶段是在不到两个月的时间内完成的,成本为266.4万个GPU小时。再加上11.9万个GPU小时用于扩展上下文长度和5000个GPU小时的后训练,DeepSeek-V3的总训练成本仅为278.8万个GPU小时。假设H800 GPU的租赁价格为2美元/每GPU小时,那总训练成本仅为557.6万美元(上述成本仅包括DeepSeek-V3的官方训练,不包括与先前研究、架构、算法、数据和消融实验相关的成本)。与GPT-4相比,上述成本不到其1/10,DeepSeek-V3的发布验证了AI大模型低成本训练的商业可行性。

(4)DeepSeek-V3创新性的架构特点是通过引入MLA实现高效推理,通过DeepSeekMoE实现成本更低的训练。
1)多头潜在注意力机制(Multi-Head Latent Attention,MLA)区别于Transformer架构的多头注意力(Multi-Head Attention,MHA)机制,显著减少了键-值缓存的内存占用。MHA通过计算查询(Query)、键(Key)和值(Value)矩阵之间的关系,使模型能够关注输入序列中的不同部分。然而,在自回归生成过程中,为了避免重复计算,需要维护一个键-值(KV)缓存,该缓存存储了所有先前生成令牌的键和值矩阵,同时带来了显著的内存挑战,制约了模型的实用性。为了解决该类问题,MLA不直接存储完整的键值矩阵,而是存储一个维度更小的压缩向量。在需要进行注意力计算时,再通过解压缩重构出所需的键和
值。这种压缩-解压缩机制使得模型可以在显著减少内存占用的同时,保持甚至提升性能。DeepSeek-V2的技术报告显示,MLA使KV缓存减少了93.3%,训练成本节省了42.5%,生成吞吐量提高了5.76倍。
2)DeepSeekMoE的基本架构建立在Transformer框架之上,在前馈网络(FFN)层引入了创新的MoE机制。与传统MoE使用较粗粒度的专家划分不同,DeepSeekMoE采用了更细粒度的专家划分方式,使每个专家能够负责更具体的任务,从而提高模型的灵活性和表达能力。具体来说,DeepSeekMoE的每个MoE层由1个共享专家和256个路由专家组成,每个token会激活8个路由专家。这种设计使得模型能够在保持高性能的同时,显著减少计算资源的消耗。不同于传统MoE中专家都是独立的设计,DeepSeekMoE的共享专家负责处理所有token的通用特征,而路由专家则根据token的具体特征进行动态分配。这种分工不仅减少了模型的冗余、提高了计算效率,还使得模型能够更好地处理不同领域的任务。
(5)DeepSeek-R1性能对齐OpenAI-o1正式版。DeepSeek-R1于2025年1月20日发布,共671B参数,激活参数37B,在DeepSeek-V3-Base基础上训练而来。DeepSeek-R1 在后训练阶段大规模使用了强化学习技术,在仅有极少标注数据的情况下,极大提升了模型推理能力。在数学、代码、自然语言推理等任务上,性能比肩OpenAI o1正式版。
(6)DeepSeek-R1表明通过强化学习可以直接提升推理能力,能够在不依赖监督微调的情况下实现强大的推理表现,同时蒸馏技术也能够将大模型的推理能力转移到更小的模型上,提升它们的表现。
1)DeepSeek-R1-Zero通过强化学习训练,展现了“自我验证、自我反思”和“生成长链推理”的能力,DeepSeek-R1在此基础上做了改进,加入了冷启动数据和多阶段训练流程,从而进一步提升了推理能力并改善了可读性。过去的大多数模型依靠大量的监督数据来提升模型性能,但监督数据的搜集耗时耗力,而DeepSeek-R1-Zero仅从基础模型开始,在后训练中通过纯粹的强化学习(RL)过程进行自我进化。为了节省RL的训练成本,R1-Zero采用了组相对策略优化(Group Relative Policy Optimization,GPRO)方法,让模型针对每个问题生成多个输出,通过比较这些输出的相对表现来调整策略。而在训练时,奖励模型(Reward Modeling)决定了模型优化的方向。R1-Zero采用了包括准确性奖励和格式奖励的基于规则的奖励系统,而没有采用基于神经网络的奖励模型,为了避免出现奖励欺骗的情况。在自我进化的过程中,随着推理运算时间的增加,模型解决复杂推理任务的能力也在不断增强,此外还涌现出了“反思”等复杂行为,模型会重新审视和评估自己先前的步骤,还会自发地探索解决问题的其他方法。R1-Zero虽然推理能力强,但存在推理过程可读性差、语言混杂等问题,因此DeepSeek-R1在R1-Zero的基础上引入了“冷启动”策略和多阶段训练,冷启动是指先用少量高质量的CoT数据对模型进行初步训练,相当于给模型一个“热身”,目标是让模型既能保持强大的推理能力,又能生成清晰、用户友好的回答。
2)模型蒸馏技术是一种将知识从复杂的大型模型(教师模型)转移到更小、更高效的模型(学生模型)的方法,旨在保持性能的同时减少计算资源和存储需求。DeepSeek-R1证明了较大模型的推理模式可以被蒸馏到较小的模型中,比在小模型上通过RL训练的推理模式表现更好。DeepSeek利用DeepSeek-R1生成的推理数据,对多个稠密模型进行了微调,结果表明,蒸馏后的小型稠密模型在基准测试中表现非常出色,其中32B和70B模型在多项性能上比肩OpenAI o1-mini